
Weekly update 2019/09/01; What I am working on
This is my first attempt to write regular weekly blogs about all kinds of stuff I am working on, so it will be a lot longer than the rest of them. I've thought about what should I write about and decided to begin with all kind of (software) pains I have.
Blog pain
My first update post, and I can already see that this blog process will need a lot of improvements.
I am using notion.so as a blogging platform, which is not ideal choice, as the notion.so is more of a personal wiki, than blogging platform.

Originally, I've used notion's "publish" function to make certain nodes, like my personal blog, public, but many people hated it. Notion loads a ton of javascript into the published site, hijacks the keyboard, scrolling and generally does all kind of weird stuff with your browser. After I've received pretty negative reactions, I've hacked together notion_blog, which is a simple static generator from the HTML export Notion introduced. It does some postprocessing on the CSS, URL's and so on.
It is still pretty lowlevel in terms of what is required by today's sites. For example, I have to generate twitter previews manually, there is no discussion, no webmentions, SEO and so on. Also, URL's are for the time being horrible, like this;
http://blog.rfox.eu/Bystroushaak%20s%20blog/English%20section/Series%20about%20Self/Environment%20and%20the%20programming%20language%20Self%20part%203.htmlWhole blog is deployed in really amateurish way. First, I request export on the notion website, select that I want HTML, sub pages, yeah, thank you very much, and then I wait until the .zip file with export is downloaded.


(I have no idea WTF is that artifact at the top of the last screenshot).


This takes minutes. Then I open terminal in the directory with the blog, run a convert script (see the github repo), which creates a map of pages in memory, links them together and does some HTML postprocessing and then dumps them all on the disk.



I then commit the changes, usually via git gui.

and push them to the server, also via git gui, with the ctrl+p shortcut:


Update in the repository is then picked up by the cron on my VPS
*/5 * * * * cd $HOME/scripty/notion_blog && git pull > /dev/null 2>&1and served via nginx on subdomain blog.rfox.eu.
Needless to say, this is really time-consuming and elaborate process, that really puts the whole idea of "simple publishing via notion" on its head.
Structural pains
Other than technical pains, I'll also have to think about the structure of the blog. There are two sections, English and Czech and both of them initially had just some nodes thrown in them. Then I've added subsections and although it works great for the categorization, it doesn't help the discoverability of the new articles.
I'll have to create some kind of feed, other than the 📰Changelog, which is used for RSS / Atom generation and is generated by the table in the Notion wiki. Something more visual and directed towards the user. Maybe some box on the left / right with last five blogposts? Something like that.
Also, there is a great pain, when you move node from one section to other, because all hyperlinks from the outside world are broken. So I'll need some kind of redirects, that will ideally work automatically. Maybe the blog generator could store URLs of all blogs and add redirects for the moved pieces? I also have to figure out how I can integrate it with nginx, so I can use proper http status codes for redirects, instead of HTML redirects.
Patreon
My last blogpost Environment and the programming language Self (part four; community, history, future and metaphysics) had actually generated more than eight thousand unique visits, which is not bad, considering that it was a technical post about forgotten programming language.
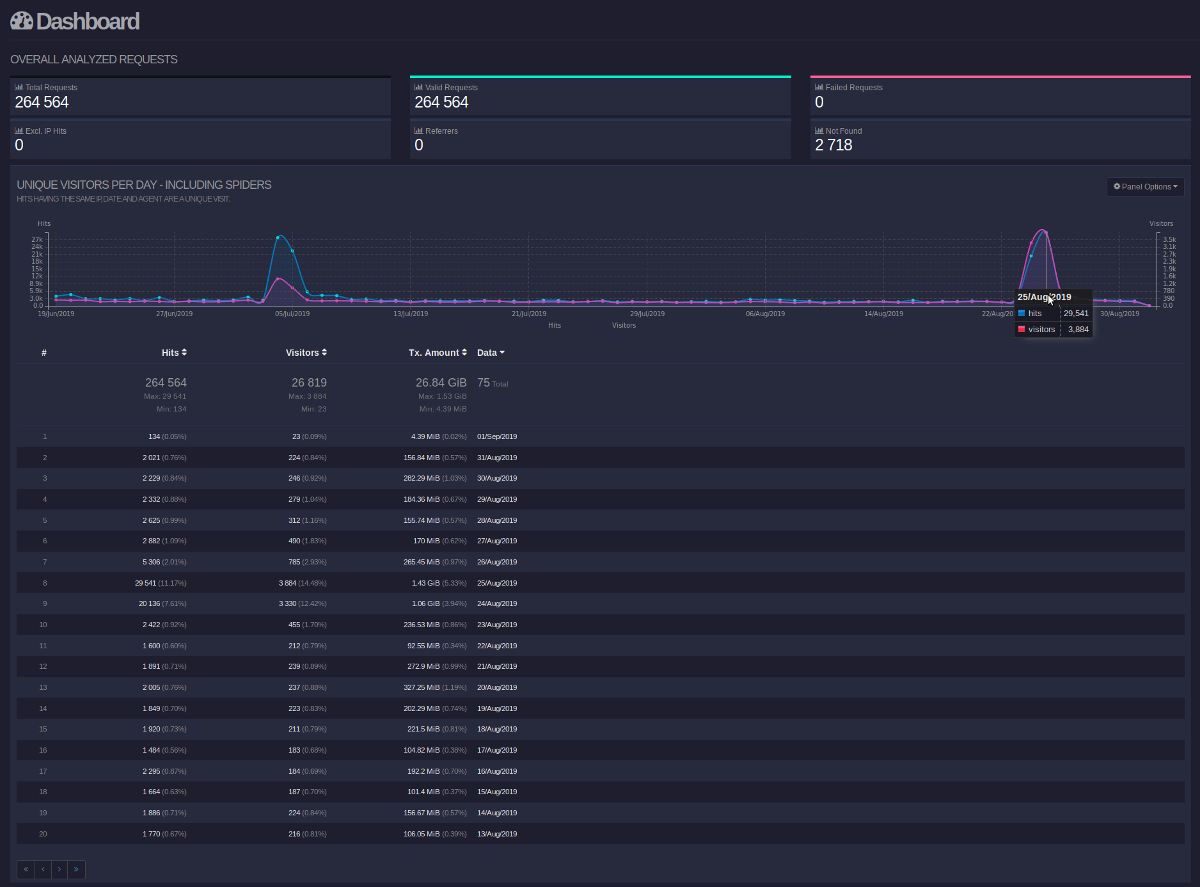
(Generated by goaccess.)
Although there is a patreon strip on all blog pages, this (by google analytics), resulted into just three visits of my patreon page. That's kinda .. sad, to the point where I am considering whether there is any point at trying to monetize the blog in this way.
I mean I don't really need this, I am just trying it as an experiment on the topic of "can I make some money by patreon?". I've decided to continue and change some of the strategies, but my expectations that this may work were downgraded.
Deployment pains
I am also thinking a lot about deployment in general. Over the years, I've created all kinds of scripts and projects. I am trying to be more conscientious about how they are deployed. Some of them were just copied with git repository on the server or VPS. Others were packed and uploaded to python package repository.
Almost none of them has logging, and configuration is often in the source code. There are no cron examples, so I usually don't have any idea how often they were meant to be running.
I am trying to map all my scripts / projects, all of their configuration, where they run, how this can be improved and automated. It goes slowly.



So far, I've concluded, that I'll need a log server, a .deb package repository, VPN that will join my whole infrastructure together and then update all my packages to support logging and single way of configuration (probably conf files in the /etc/.. and ~/.config/..).
Then I'll need some kind of orchestration (ansible?) and config management. Then I'll be happy with my infrastructure. Probably. Maybe.
Mind maps pain
I am trying to get reflection on my life, and I am thinking about all kind of stuff around me. Personal wikis are not enough, so I am trying to use mind maps. I have some success with Xmind and Edraw MindMaster, but I find them both stupid.

I won't even go into the topic of OpenSource mindmapping software, because they are generally annoying and not intuitive at all and get in the way of thinking, which makes them unusable.
Xmind on the other hand have really beautiful and simple user interface:
and it is generally pleasure to work with.
Sadly, both of them try to impose all kinds of limitations on you. For example, they try to force you to use Mind maps, and not Concept maps. Difference is, that Mind maps have one central node, while Concept maps have multiple and generally create graphs.
There is also limited formatting of the text in the nodes, no API in the programs, so you can't work with the mind maps from tools outside. Imagine, that you would for example create a mind map that would represent a distributed process and pushed updates on various nodes, that would turn them green or red based on whether the node is up and running, or not. Or maybe to visualize all Issues in your github project in the mind map and automatically move them between nodes based on status. Or maybe to give them color. Or maybe move information in other direction - to create Issues from nodes in your mind map.
I've crashed into the depression with this when I've tried to create something like this for tinySelf. I wanted to create a mind map of everything that is necessary for the first beta version:

And then I've thought; hey, this it would be nice if it could be connected to github. In the end, I've managed to put the mind map into the README, so that it is updated every time I export the image on the disk. Image is grabbed by backend utility via syncthing and published on my VPS, from which it is included to the README.

I am a bit proud of this, but it is still retarded compared to what I would love to do. That is to communicate with the process of the mind maping software itself, ideally in the both directions, and ideally in form of (Smalltalk / Self) objects, not some retarded REST/JSON (although even that would be great).
At least the format itself is kinda open, so there is at least some hope for structural exports there.
Wiki pain
I fucking hate notion.so. Really. I also love it, so there are mixed feelings.
I use two personal wikis at this moment; CherryTree and Notion.
CherryTree is this wonderful desktop program that lets you write into the nodes and is generally really pleasant to work with.

I really like to work with CherryTree, but it is really not best for what I need. First of all, it really doesn't work well with pictures. You can include them and also resize them, but that's about it. It doesn't scale good with the single sqlite file CherryTree uses to store all its information and also it breaks the HTML export in many strange ways.
CherryTree also can't do all kinds of other stuff notion does well. Tables for example. Date points. Views on data, like kanban boards.

Notion on the other hand is really next generation software, it's creators were inspired by the Engelbart, and you can really see it. But it is not there yet, and also it is built on the pile of shit casually called "modern web technologies". It's often slow and annoying, full of javascript. It tends to lock all your data to their servers, and there is no official API yet and the unofficial API is full of JSON via REST, where you end up iterating over hundreds of random JSON """objects""", and it is generally really shit to work with (I know because I use it to generate RSS feed for my blog from the notion table).
I am working on my own idea of the personal wiki, but that is blocked by ..
tinySelf pains
📂tinySelf is my pet programming language, inspired by Self and Smalltalk.
I am working on it because I want to experiment with the platform for the information representation and storage, that is also a programming language. I've always thought, that SQLite is a great idea. Now imagine, that SQLite wouldn't use database cobol SQL for the programming language, but something more sane, like Self, which is a language similar with features and syntax to Smalltalk, but using prototypes instead of classes (see 📂Series about Self for details).
This combined with the Morphic user interface could really be the killer app for the creation of personal wiki's, but also all kind of tools for work with information. Mind maps are another example. Exocortex in general.
This is of course really ambitious project, that will take me many years. It already took more than year and a half.
Right now, I am preparing to release first public version of the tinySelf, which is at the moment just a simple Self-like language.
In the process, I am constantly running in all kinds of pain. My latest pain is when I've fixed behavior of the blocks (equivalent of closures / lambda functions) and it broke several other parts of the interpreter in ways that are really, really hard to debug.
At the moment, I am trying to solve problem caused by some weird kind of caching, where there shouldn't be any. This causes messages to block work on first time, but then when you try to send message to different block, it is sent to the first one again, which is super weird and really hard to debug.

I've spent more than 10 hours by debugging this problem in the last week. I've fixed several bugs found in the meantime and I feel like I should take whole tinySelf, throw it out of the window and use something more mature, like Pharo. But Pharo is class based and also really not that much hackable, and I've already tried and it didn't work well.
Book pains
I've bought a book about rust.

I've worked with Rust before, and I generally consider it really nice language. I want to formalize my knowledge about it, but I've been unable to get into the book because other books took my time.
I've also bought a chair, and I am trying to read more systematically all the books I want to read.

Right now, this is a top of my stack (which contains dozens of books at the moment):

Especially GEB really takes my time, because my progress through it is really, really slow.
So, every day, I sit in the chair around midnight and I try to read a little through all the books around the chair. I've almost finished books on the left (Moldable tools and 97 klíčových znalostí programátora), but my overall progress of downloading information into my brain is (as always) slower than expected.
Other than that, I read on my ebook reader, mostly sci-fi. I've finished Aristoi yesteday, and I didn't liked it much.
I want to try to update my reading habit, to read in a more sane time, like 22:00, instead of midnight or 1 am like now.
Procrastination pains
I think that I spend too much time by reading articles on the internet. I'll probably try to log all the articles I'll read in the next week to just put this into numbers.
Yes, my English is probably horrible, but this kind of blog doesn't qualify for (paid) grammar corrections. If you want to change this, subscribe to my patreon.
